1. 객체 탐지(Object-Detection)와 RetinaNet의 등장 배경
객체 탐지(Object-Detection)은 이미지에서 객체의 위치와 종류를 동시에 알아내는 컴퓨터 비전 기술입니다.
크게 보면 Two-stage 방식과 One-stage 방식으로 나뉩니다.
- Two-stage 방식 (ex. Faster R-CNN)
먼저 후보 영역(Region Proposal)을 뽑고, 그 후에 클래스를 예측합니다.
이 방식은 두 단계를 가지기 때문에 정확하지만 구조가 느리고 복잡합니다.
- One-stage 방식(ex. YOLO, SSD)
이미지 전체를 한 번에 처리하며 빠른 속도가 장점입니다.
하지만 Two-stage에 비해 정확도가 낮다는 게 단점이었습니다.
이런 구조적 차이 때문에 One-stage 방식은 늘 속도가 빠르지만 정확도에서는 부족했습니다.
그 이유 중 하나는 학습 중 배경(background)의 수가 너무 많고, 정답 객체는 너무 적다는 불균형 문제 때문입니다.
이 문제를 정면으로 해결한 논문이 바로 Focal Loss for dense Object Detection입니다.
Dense Object Detection이란?
-> 입력 이미지의 모든 위치(grid cell)마다 사전 정의된 여러 anchor 박스를 기반으로 객체를 예측하는 방식을 의미한다.
2. RetinaNet의 구조: FPN과 분리된 두 서브넷
RetinaNet은 단순하지만 강력한 구조를 가집니다.
크게 보면 다음 세 단계로 나눌 수 있겠습니다.
1) Backbone: ResNet + FPN

백본에서 추출한 feature를 기반으로, top-down 경로와 lateral connection을 결합하여 FPN의 피처맵(P3~P7)을 구성합니다.
이 구조는 다양한 해상도의 피처맵을 동시에 활용할 수 있도록 하여, 다중 스케일 객체 탐지라는 새로운 패러다임을 제시했습니다.
2) Detection Head (서브넷)

* 이 부분에서 주의할 부분은, FPN의 각 레벨(P3 ~ P7)의 feature map이 upsampling 없이 그대로 서브넷에 전달된다는 것입니다.
Classification 서브넷은 다음과 같이 구성됩니다:
(3 * 3 conv, 256 filters + Relu) * 4 + (3 * 3 conv * num_anchors filters * num_classes)
-> 각 위치의 anchor에 대해 클래스별 확률을 출력합니다.
Box Regression 서브넷도 유사한 구조이며:
(3 * 3 conv, 256 filters + Relu) * 4 + (3 * 3 conv * num_anchors * 4 filters)
-> 각 anchor가 ground-truth box로 가려면 얼마나 이동(offset)해야하는지를 예측합니다.
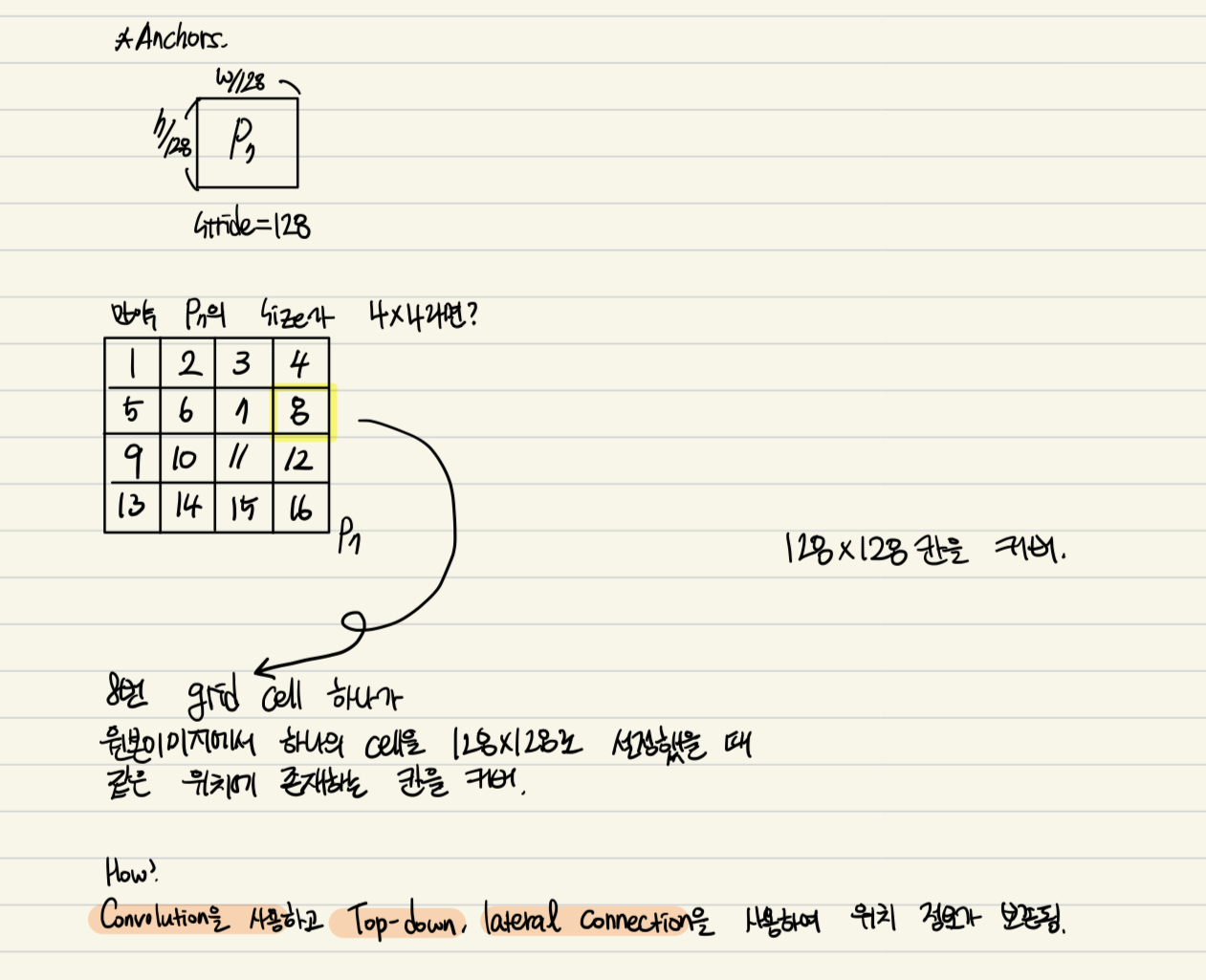
3) Anchors
(이 개념을 이해하는데 한참 걸렸습니다. 부디 이 글을 읽으시는 분들은 빠르게 이해하시길…)

RetinaNet에서는 각 위치마다 3가지 scale과 3가지 aspect ratio의 조합으로 총 9개의 anchor가 정의됩니다.
- 3가지 스케일 = {1.0, 2^(1/3), 2^(2/3)}
- 3가지 aspect ratio = {1:1, 1:2, 2:1}
이러한 anchor는 FPN의 P3부터 P7까지의 feature map 위에 배치되며(각 셀마다 위치),
각 피처맵의 해상도(stride)에 따라 anchor의 크기도 달라집니다.
예를 들어, P3는 stride 8이므로 원본 이미지의 8×8 픽셀 영역마다 하나의 픽셀로 매핑되고, P7은 stride 128로 128×128 영역을 담당합니다.
즉, FPN feature map의 각 픽셀은 원본 이미지에서 특정 위치를 대표하며,
그 하나의 픽셀 위에 9개의 anchor box가 배치되는 구조입니다.
이처럼 stride가 클수록 큰 객체를 담당하고, stride가 작을수록 작은 객체를 담당하게 되어,
RetinaNet은 한 이미지에서 수만 개의 anchor를 조밀하게 생성하며 작은 물체부터 큰 물체까지 폭넓게 탐지할 수 있는 기반을 갖추게 됩니다.
요약
FPN 레벨의 픽셀 = anchor 중심점
- 픽셀마다 anchor 9개 (scale × aspect ratio 조합)
- stride가 커질수록 큰 anchor, 적은 해상도
- P3~P7 전체를 활용하여 다중 스케일 객체를 효과적으로 처리
3. RetinaNet의 학습 방식: Anchor 기반 학습
RetinaNet은 anchor 기반 dense detection 모델입니다. 한 이미지당 수만 개의 anchor가 존재하고, 이들 각각에 대해서 학습 여부를 판단합니다.
1) Label 정의 방식
각 anchor에 대해서 GT box와의 IoU를 계산하여 다음 기준으로 라벨을 지정합니다.
- IoU >= 0.5 -> Positive (foreground)
- IoU < 0.4 -> Negative (background)
- 그 사이 [0.4, 0.5) -> Ignore
2) 학습 손실 구성
- Classification Loss는 Focal Loss를 사용합니다.
- Regression Loss는 일반적으로 사용하는 Smooth L1 Loss입니다.
- Positive anchor(foreground)만 Regression 대상이 되며, Negative anchor(background)는 Classification에서만 계산합니다.
이러한 학습 방식은 기존 모델보다 더 많은 anchor를 다루면서도, 정확하게 학습할 수 있습니다.
4. Focal Loss: 불균형 문제를 해결한 핵심 아이디어
기존 CE Loss는 쉬운 배경 샘플이 너무 많아 전체 손실에서 지배적인 비중을 차지합니다. 이로 인해 모델은 진짜 어려운 소수의 객체 샘플을 잘 학습하지 못하게 됩니다.
이를 해결하기 위해 RetinaNet은 다음과 같은 Focal Loss를 제압합니다.
Focal Loss: 수식 배분과 그래프 해석 - https://small0753.tistory.com/m/30
Focal Loss에 관련한 내용은 해당 블로그에서 볼 수 있습니다.
5. RetinaNet이 남긴 의의와 방향
구조적 의의
RetinaNet은 FPN과 두 개의 head라는 간단한 구조만으로도 Two-stage 모델을 능가하는 정확도를 달성하며, 이후 등장한 수많은 객체 탐지 모델에 지속적인 영향을 끼친 모델입니다.
무엇보다도 Focal Loss는 손실 함수 자체의 설계를 통해 class imbalance 문제를 구조적으로 해결했다는 점에서, 객체 탐지 연구의 패러다임을 바꿔놓았다고 할 수 있습니다.
이후 객체 탐지 분야는 anchor-free 방식, attention 기반의 head, transformer 기반 backbone 등으로 빠르게 진화하고 있지만, RetinaNet은 그 시작점에서 “One-stage 모델도 정확도와 효율성을 동시에 추구할 수 있다“는 가능성을 증명해낸, 전환점이 된 모델이라 할 수 있습니다.
⸻
그리고 이 블로그를 마무리할 즈음, 저에게 이런 생각이 들었습니다:
“그런데, 왜 하필 RetinaNet 구조였을까? 다른 구조였다면 가능했을까?”
“왜 백본으로 ResNet을 썼을까? 많고 많은 다른 네트워크들도 있는데…”
사실 RetinaNet은 완전히 새롭게 모든 걸 설계한 모델이라기보다는, 그 당시까지 검증된 기술들을 아주 영리하게 통합한 구조입니다.
• FPN은 이미 Faster R-CNN에서 뛰어난 성능 향상을 보여주며 다중 스케일 표현의 강점을 입증했고,
• ResNet은 깊은 네트워크에서도 안정적인 학습이 가능하다는 점에서 가장 신뢰받는 backbone이었으며,
• Anchor-based 구조는 SSD 등의 모델에서 성공적으로 활용된, 당시로선 가장 범용적이고 직관적인 detection 프레임워크였죠.
즉, RetinaNet은 새로운 아이디어(Focal Loss)를 안정적인 구조 위에 실용적으로 얹은 모델이었고, 그것이 이 모델이 널리 사용되고 후속 모델들에게까지 영향을 줄 수 있었던 핵심 이유였습니다.
6. 마무리
RetinaNet은 단지 모델 하나가 아니라 One-stage 객체 탐지기의 한계를 구조와 손실 함수 설계로 극복해낸 사례입니다.
객체 탐지를 공부하거나 구현해보고 싶은 분들에게 RetinaNet은 반드시 한 번 짚고 넘어가야 할 기준점이라고 할 수 있겠습니다.
Reference:
Focal Loss for Dense Object Detection: https://arxiv.org/abs/1708.02002
